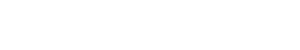

Calculating… Calculating… DOCSIS Codeword Errors – You will likely see them
DOCSIS correctable codeword errors and uncorrectable codeword errors are available as a metric in most cable operator monitoring tools and Operations Support Systems (OSS). The monitoring tools and OSS generally provide data and dashboards for users to monitor overall network health and then identify a problem when it occurs. Metrics like codeword errors are extracted directly from DOCSIS CMTSs using Simple Network Management Protocol (SNMP) or Internet Protocol Detail Records (IPDR), the later being preferred due to its reduced CMTS CPU utilization. What many people struggle with are what are those codeword errors, what do they mean, and how bad is bad? This artical will answer those questions and discuss Reed Solomon forward error correction including how it corrects bit errors in the DOCSIS network.
Where Codeword Errors Come From
When someone is using a device, such a PC or iPad, and transmits data over a DOCSIS cable modem that larger than 16 bytes of data, an error protection algorithm kicks in called Reed-Solomon (RS) forward error correction (FEC). There are two parts to RS FEC, one is the encoder, which is in the cable modem and the second is the decoder, which is in the CMTS. As an example, the RS encoder creates an 18 byte codeword from an original 16 bytes of data transmitted by you, the user. The two extra bytes of data are added for error correction. The 16 bytes of data plus the 2 bytes of FEC is called a codeword. Great, so we have two bytes of data for error correction added and we know the origin of the mysterious codeword, but now what? How does two bytes of data help us and where do correctable and uncorrectable codewords come from? First, lets understand how the 18 byte codeword was initially formed in the DOCSIS cable modem so that we better understand how the two error correction bytes will help us when we need them. The original 16 bytes are inserted into a matrix as shown below. Each byte is represented by B1 for byte #1, B2 for byte #2, you get the picture. Next, each row in the matrix gets some complex math applied to it using something called a polynomial in order to create a value for each row listed, such as y1. Similarly, each column gets complex math applied to create values such as that displayed by x1 (using that same polynomial). Those are not the actual values, but I don’t want to put you to sleep with algebra.

Finally, the horizontal math values and vertical math values are also put into one final polynomial to create the 2-byte word which is called the parity-bytes in DOCSIS terminology (shown in the red box). If you are interested in the math behind calculating the parity-bytes, check out the DOCSIS standard. Further, I have used a very basic example of 16-bytes for illustration purposes. DOCSIS defines an algorithm by which data packets larger than 16-bytes can be accommodated.
Now that we understand how the RS codeword was formed, we can discuss how errors occur. As the codeword is passing through the HFC network as an RF signal it is likely to experience RF impairments. Let’s say that this particular codeword experiences a brief moment of laser clipping which only impact one byte of the matrix. Shown below is the impacted byte (in red). Here is where the Reed Solomon algorithm in the CMTS works its magic.

Byte B7 is displayed as red, indicating it was the cell that received errors. The RS algorithm was able to determine this using the inverse equations used to create the parity-bytes. First it extracts the vertical and horizontal values and displays their x & y values. Next it calculates the vertical and horizontal values based upon the received data. But what happens is that the received data has a corrupt cell at B7, so its vertical and horizontal values do not match up with those that were created from the parity-bytes. This could be a correctable or uncorrectable codeword error, but we don’t yet know.
How Many Errors Can FEC Correct?
So far I have mainly been talking about FEC in terms of bytes because this is how DOCSIS refers to FEC granularity. But RS FEC matrices like the two I illustrated above use bits. There are eight bits in a byte. A bit is also the smallest value in terms of logic because it is either a one (1) or a zero (0). This is quite helpful in the previous example where we had an error that was detected by RS. If RS detects an error in a matrix cell all it has to do is change the value. What do I mean by this? If there is a one (1) in the cell and the parity-byte says that cell is wrong, then by changing it to a zero (0) and re-running the algorithm and checking it against the parity-byte again it will be correct. That is how correctable codewords work! The RS algorithm sees an error, flips the value, checks it again proclaims “hey, we had an error but we fixed it, so just keep on going and call it a correctable codeword.” Okay, maybe I’m embellishing for the CMTS, but it deserves some credit. There is a point where too many errors cannot be corrected. This point occurs at different times for different modulation rates, but based upon the Reed-Solomon algorithm can be generalized using the following equation (this is really basic, so don’t panic):
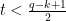
where t = number of correctible bits, q=codeword length (18 bytes in this example), k = data length (16 bytes in this example). Now if we just plug the values into the above equation, we can find out how many bits of data that RS will be able to correct for this codeword.

Since 1 byte (B) = 8 bits:

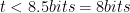
Therefore, in the example used here, RS should typically be able to correct about 8-bits or 1-byte worth of data. This means the error created back in our example would have been a correctable codeword! When RS exceeds its ability to correct data, say t = 9 bits, then it will report an uncorrectable codeword and the CMTS will delete the codeword. This means the packet will need to be retransmitted if it is non-realtime data, but if it is voice or video traffic then its gone for good. Uncorrectable codeword errors in a DOCSIS network is a sure sign that a subscriber somewhere on your network is losing data. If you have large amounts of uncorrectable codeword errors then you can speculate that you have a dissatisfied customer, but don’t speculate that you have issues in your network because it is a fact that you do.
Codeword Errors on a CMTS
A lot of users or even SNMP-based systems will look at codewords and correctable / uncorrectable codewords directly from a CMTS. The commands are pretty straight forward and look like this:
volpefirm# show interface c1/0 upstream
Cable1/0: Upstream 0 is up
Received 2112 broadcasts, 4045 multicasts, 3398631 unicasts
0 discards, 3166 errors, 2581 unknown protocol
3404788 packets input
Codewords: 13861878 good 760804 corrected 47090 uncorrectable
5 noise, 0 microreflections
Total Modems On This Upstream Channel : 7 (7 active)
On this upstream port you can see there are a lot of corrected and uncorrectable codeword errors, but how do you determine if this is good or bad? First you want to convert the correctable and uncorrectable codewords into a percentage based on the total number of codewords. This is easy to do using the following formula:
Uncorrectable Codeword Errors %=((Number of Uncorrectable Codeword Errors )/Total Number of Codewords)×100
It is important to read the details in the management information base (MIB) objects for SC-QAM codewords.
The description for docsIf3CmtsCmUsStatusUnerroreds is as follows: This attribute represents the codewords received without error from the CM on this interface. Discontinuities in the value of this counter can occur at re-initialization of the managed system, and at other times as indicated by the value of ifCounterDiscontinuityTime for the associated upstream channel.
The underlined section clarifies that in the MIB object for total codewords, the attribute named “docsIf3CmtsCmUsStatusUnerroreds” specifically counts only those codewords that are error-free. This indicates that both correctable and uncorrectable codewords are not included in what is defined as the “Total Number of Codewords” by this attribute. It’s crucial to understand that for accurate percentage calculations, the “Total Number of Codewords” in the denominator of our formula should encompass all codewords—this includes the total codewords, along with both correctable and uncorrectable ones, even though this comprehensive inclusion is not explicitly specified.
Here is the complete version of the SC-QAM formula for uncorrectable codeword errors, with the added clarity in the denominator:
Uncorrectable Codeword Errors %=((uncorrectable codewords )/(total codewords + correctable codewords + uncorrectable codewords ))×100
While this appears to be a minor change, it can have a significant impact on the percentage error, depending on the variables in the denominator of the equation.
The same formula applies for correctable codeword errors. While a correctable error rate of over 5% seems high, it is important to keep in mind that the CMTS is fixing these errors. The uncorrectable errors are something to be more concerned about because these errors result in lost data. For voice-over-IP (VoIP), the recommended best practice is not to exceed 1% uncorrectable codeword errors. In addition, one thing that you will want to look for are trending patterns, such as increasing correctable and uncorrectable codeword errors over an extended period of time such as days, weeks or months. This is an omen of certain bad things to come in your DOCSIS network. This should have provided a good starting point for those not familiar with Reed Solomon error correction and codeword errors. In a future post I’ll correlate how codeword errors an bit error rate can be related. This is especially valuable for those who use test equipment to help resolve field issues, but only have pre- and post-FEC measurements to rely on. Upcoming events can be seen under Broadband Events. Previous events can be seen under the blog.
- If you are watching this on youtube please hit the subscribe button!
- Let us know what you think and remember to share!
- You can find slides at the bottom of the page and some on slideshare.
- Find out about events or articles by following us on Twitter, LinkedIn or Facebook too.
Also available on iTunes, Google Podcasts, Spotify, vurbl see podcasts “get your tech on”. ![]()
![]()
![]()
![]()


Brady,
Informative as ever-I look forward to the next article on codewords. One thing I’ve never fully understood is the relationship between codewords and packets.If we say the “average” packet is 1500 bytes long, in general, how many codewords would need to be generated to get this packet from the susbcriber, to the CMTS? Other articles suggest codewords being about 256 bytes “worth”, but you mention 16 bytes-is this the same for every codeword? And then we can ask how the likes of concatenation and fragemention affect these as well.
For me, this really is the nuts and bolts. and would then let me understand fully the realtionship between packets and codewords, and then (maybe) come up with BER figures, as well as the current MER that we use.
Cheers
Hi Sandy,
Thanks for the feedback. I’ll hold off on the math for now as its more complicated than what easily fits into a comment reply, but as you suggested, this would make for great article, so I’ll put it on my map.
-Brady
Hey “Sandy”,
It took me awhile to figure out your code name until we shipped you the posters. But now I know. 🙂 Hope those make it to you okay.
Thanks for the feedback on the article. I used 16-bytes in this article because I wanted to be able to visually explain the matrix. Using larger packet sizes made it hard to fit on the page. Give me some time and I’ll do a follow-up article to describe in more detail how this scales. I was planning to do it in MATLAB and provide the code so that folks could download the student version if they did not have a copy and play with it.
However as a quick answer, you can take the math I did in the article and scale it accordingly for the first equation under “How Many Errors can FEC Correct?”. Also, there is a relationship between this, codeword errors BER. I’ll include that in a future article also. Sorry about being slow on articles lately, but my clients have been keeping me busy.
Regards,
-Brady
Brady,
Got the charts, many thanks! Look great.As for the Sandy part 🙂 , its my middle name, which I prefer to use on public sites.
Thanks for the reply on the codewords, I’ll await a further response when you get the time..
It’s a hot topic over here at the moment, and all the docs I’ve read have never been able to slice up a Ethernet sized frame into codewords, thereby giving us some idea how many codewords “lost” translate into actual packet payload-and therfore the customer experience.
Cheers
Sir,
What is the best method of tracking FEC in a Cable System? Currently I am Pulling the Fiber to determine with Node the Issue is coming from(because we are 4 to 1). Most of the time when I pull the fiber the FEC issue goes away, but I would like to know if there’s away to track it without pulling the fiber in the Hub so that I can actually fix the issue causing the FEC. Any suggestions? Also once I determine the Node I am pulling return pads to track it from there.
Thanks,
Hi Scotty,
When you say “What is the best method of tracking FEC…”, I am assuming that you already know that you have correctable and uncorrectable codeword errors because you are in the headend and pulling on fibers. You are likely seeing the errors by looking at an SNMP monitoring system or by looking at the SNMP CLI, correct?
I generally recommend using a test instrument such as a spectrum analyzer or return path monitoring system at the same time that you making any type of changes in the headend (i.e. pulling on return path fibers) to see what impact that is having on the return path spectrum. In your particular case, it sounds like you could be dealing with dirty, loose or damaged return path fiber connectors. I wrote an article that covers some of this. You can check it out HERE.
A good spectrum analyzer that allows you to display multiple traces (peak hold, live trace, average, and minimum hold) like the AT2500 from Sunrise Telecom is very helpful for any type of live plant testing. You need something very responsive.
Pulling return pads is also a pretty common troubleshooting practice. It can be disruptive to the subscriber, especially if you have Voice subscribers. Plus you likely have to do this during a maintenance window, which means yet another night of no sleep for you. I recommend one of two methods for this which is better for you and the subscriber. Several vendors offer equipment that let you inject a return signal to a headend monitoring system which will check for error rate plus impairments. These work like DOCSIS signals (one is integrated into the DOCSIS network itself). All have their pros and cons, but its a lot better and provides more information than pulling pads.
-Brady
Hello Brady –
Relative to computing the percentage of corrected and uncorrectable codewords, I’m questioning the math in your example:
Codewords: 13861878 good 760804 corrected 47090 uncorrectable
You used the ‘good’ codewords as the total codewords. However, if corrected and uncorrectable are stated separately from the good codewords, would not the total codewords be the sum of the three?
Thereby, the % of uncorrectable codewords would be (47090/14669772)*100 = .3210%
rather than (47090/13861878)*100 = .3397%
In this example, the difference is very nominal; however, for some, this difference may end up being quite significant.
Fantastic job on your blog! Your time and effort is most appreciated!
Hi Elaine,
This is a very good point you make and I glad that you brought it. I agree with you that in some cases it will have a nominal impact. However if you reset your counters on a daily basis and have high codeword error rates, then the impact could be greater. I am now interested to find out if anyone is using an algorithm other than the one I mentioned in my post that takes into consideration what Elaine mentioned.
I will look into this, but if anyone reading this is away that their correctable and uncorrectable error dashboard removes the errors from total codewords first, before dividing please post back here to let us know.
-Brady
Actually, in our product. we use CER = uncorrectable/(good+correctable+uncorrectable). we are not remove errors from total codewords.
Brady,
I think there would be merit in explaining how USCER data is different for upstream and downstream. The systems we use to monitor give us the uncorrectable rates, usually in scientific ratios, 5.21E-7 for example. This is based on the math you explained above. The upstream isn’t a constant flow of data, and after correcting a fault causing errors, a quiet modem will not report an improved error rate until it passes enough data (thru station maintenance) to make an accurate calculation, yes? The same holds true for that modem’s reported USSNR, right?
Obviously, the downstream is different because of the constant flow of data to every device is used for these calculations, whereas the upstream is bursty, and as I put it, “modems only talk when spoken to”.
Hello Brady
When considering metrics via SNMP would you suggest capturing each instance of a given metric or just capture the one instance and use that for the overall measurement? Performing statistical analysis on each instance will be a very thorough approach but I’m not sure that the added complexity is really necessary. Your thoughts?
Hi John,
you can never take a specific measurement in time and assume accuracy. There are too many variables. It’s best to have a start point and an end point to do delta readings in a specific time period.
Hello Brady
Could you recommend acceptable Upstream Codeword error ratio, correctable ratio, uncorrectable ratio?
1. per cable modem
2. per upstream channel
Thanks
Jerry
Hi Jerry,
Thanks for reading and the question. Your question was selected to be part of our podcast. You can watch or listen here. https://volpefirm.com/docsis-cmts-best-practices-recommendations/
Thanks or your interest.
Mia
Hi Brady,
We had a internal discussion about CER and CCER and stumbled upon this topic on your site.
Thanks for all the effort you are putting into the socials
your formule is:
correctable codewords = corrected codewords/total codewords*100
The calculation on this website is
correctable codewords = 760804 /13861878 *100
In our opinion this should be
correctable codewords = 760804 /(13861878+760804+47090 ) *100
As the total is 13861878 good 760804 corrected 47090 uncorrectable = 14669772 in total
Or do we miss the point somewhere.
Regrads
Bram and Ronald